
Top Generative AI Product Gaps to Invest In
Seven pernicious gaps that impact builders of GenAI products and a brief review of the companies working to close them.


The past decade has seen no shortage of companies that support building with traditional AI technologies; however, the landscape supporting generative AI builders is in its infancy. As the capabilities of foundational large language models (LLMs) like ChatGPT, Claude, Llama, and Gemini advance, and as more product teams discover novel use cases for them, the complexities of putting them into practice at production scale and quality are rapidly emerging, presenting a lucrative opportunity for founders and investors alike.
This post explores seven product gaps we have witnessed repeatedly in startups through public companies since ChatGPT 3.5 took the world by storm in November 2022. We share insights into the nature of each challenge and why it exists, and do our best to highlight the nascent solutions offered by innovative companies seeking to address these issues. Every gap is one where we have seen developers spend considerable time and energy writing custom code to solve important problems. We cannot say with certainty when no solution exists, but we can say that strong ones have not achieved wide adoption across these seven areas, creating a massive set of opportunities.
Disclaimer: The author is an investor and shareholder in some of the companies mentioned in this article. All research and analysis presented are based on publicly available information.
Gap 1: Guaranteeing predictable outputs
When product development teams integrate LLMs into their software architecture to solve customer problems, those models must interact with non-LLM services, which expect consistent inputs. LLM outputs can vary considerably, yet the result must be consumable by subsystems that cannot interpret large bodies of unstructured text. The systems that process information immediately after the LLM can easily fail if the LLM does not provide a predictable response style. For example:
The AI is asked to summarize a large body of emails and display those in a mobile-friendly design, with a place for the summary and some derived metadata such as “Topics.” However, because the length, formatting, and style of the summaries are inconsistent coming out of the LLM, the UI breaks, text wraps unnaturally, and expected fields like “Topics” can receive nonsensical responses.
In cases where the model is asked programmatically to produce JSON responses for consumption by downstream services, the range and formats of the values are not always respected. For example, a field that represents a score from 0 to 100 might return a score outside of that range, or the system could generate a value that is not in an expected list of possible enumerated values, such as returning “autumn” when only “summer, fall, winter, and spring” are valid and expected.
LLMs are designed not to return the same response every time. In fact, this non-deterministic architecture and sampling of information keeps the models feeling more “human” and “creative.” If we ask people to identify the top presidents of the United States, we will receive varied responses. This variance is fine in humans and machines alike, but we want all participants asked to provide the same number of “top” presidents and we’d like those responses to be in the same format, for example: full name, then years as president as eight-digit ranges, and country (ideally U.S.). When we receive results outside of these bounds from a machine, it breaks our interfaces, downstream services, and data models.
Fortunately, there are solutions for this gap. Most people improve their outputs through prompt engineering, or in this case more clearly specifying the desired response constraints. For example, instead of “Who are the top U.S. presidents?” we try “Who are the top U.S. presidents, list only 5, and list each one’s full name and year range as president.” This helps significantly, but it does not guarantee the response style. If your product uses OpenAI, you can take advantage of OpenAI’s “Functions,” which allow developers to specify the outputs they wish to receive. However, OpenAI includes an ominous warning in its documentation for Functions:
“We strongly recommend building in user confirmation flows before taking actions that impact the world on behalf of users (sending an email, posting something online, making a purchase, etc.).”
Palantir’s Artificial Intelligence Platform offers a no-code solution that combines this capability on top of multiple foundational LLMs. This is a powerful solution that would require a lot of custom code, especially when many models are used together, to get the best response in an ensemble setting.
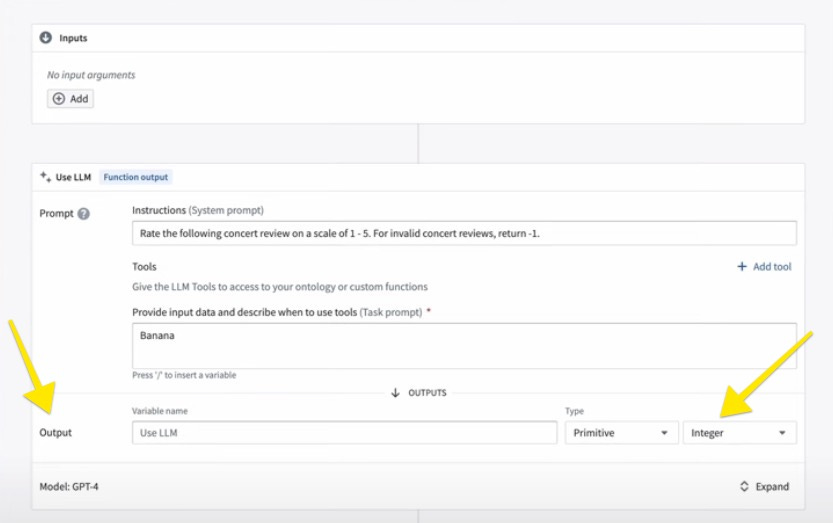
“Developing Your AI Intuition” Palantir product video showing its AI Platform (AIP)
Finally, WhyLabs.ai, a Series A startup out of Seattle, provides a full set of observability and security functions that can assist in similar applications. CrewAI can also assist here by using multiple agents to check the responses of earlier ones in the process. However, while all of these products have made some progress in enforcing strict response formats, most options appear to stop short of handling entirely incorrect, albeit well-formatted, responses without additional logic built in (See Gap 6). Ask an LLM to generate a set of latitudes and longitudes on land, and it’s possible to get a set that look real and have the proper format but that don’t respect the true constraints of latitude and longitude (for example, latitudes cannot be over 90) or that produce ones inside bodies of water instead of on land.
Gap 2: Searching for answers in structured data sources
LLMs are predominantly trained on text data, so they inherently struggle with tabular structures and NoSQL information. The models are expecting certain words and thoughts to come before and after certain other ones, like in a paragraph of written text. This inherent structure within unstructured text data is what gives meaning to the words on the page. Although models can interpret individual rows or records in structured data stores, they struggle to understand the implied relationships that may exist between records, or in the reverse, they assume relationships between records that are physically proximate when no connection exists. Additionally, many structured data sets use schemas specific to the companies maintaining the data. These schemas may not have meaning to the models themselves because the models have not been trained on the names and meanings of the data fields used.
For example, a field for “location” can largely be understood as there are many references to locations in the text that these models are trained on. However, a field that is called “resolution” with scores from 1 to 5 is not set up in a way where the model knows if 5 is good or bad, and thus the model will struggle to answer questions that correlate strong resolution of customer support issues with the circumstances of the case without some clarification first. Additionally, there is no guarantee that the LLMs won’t make up records by sampling data from multiple records or rows.
This is problematic because some of the most powerful problem statements in product require total accuracy and precision and come at the intersection of structured data sets and unstructured ones. Financial analysts performing an audit or preparing a financial report, health professionals reviewing historic notes and patient test measurements, and military planners executing lethal operations based on remote signals combined with narrative intelligence cannot take these sorts of risks. In these fields and many others, developers are spending significant extra time and code wrangling the LLMs for accuracy against structured data sets.
In fact, what we have seen most commonly is that developers will use the LLM to construct and dispatch a traditional, non-LLM-powered search to a database and return only the result to the LLM for summarization, since the LLM cannot be trusted to interrogate the structured records. It’s telling that ChatGPT does not try to use its LLM on structured data either—as of this writing, if you upload a structured spreadsheet and ask a question and check the source, you will find that it is using the LLM to write Python code to do the retrieval using a Pandas data frame, not the LLM itself.
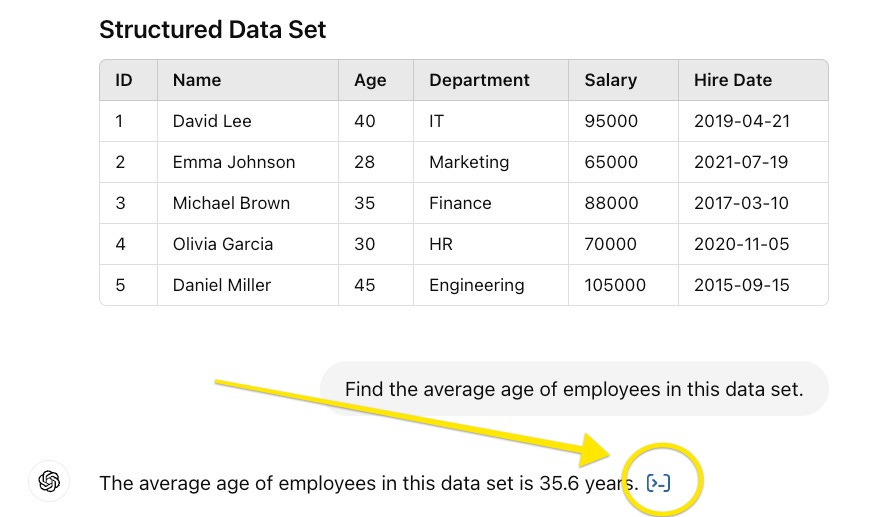
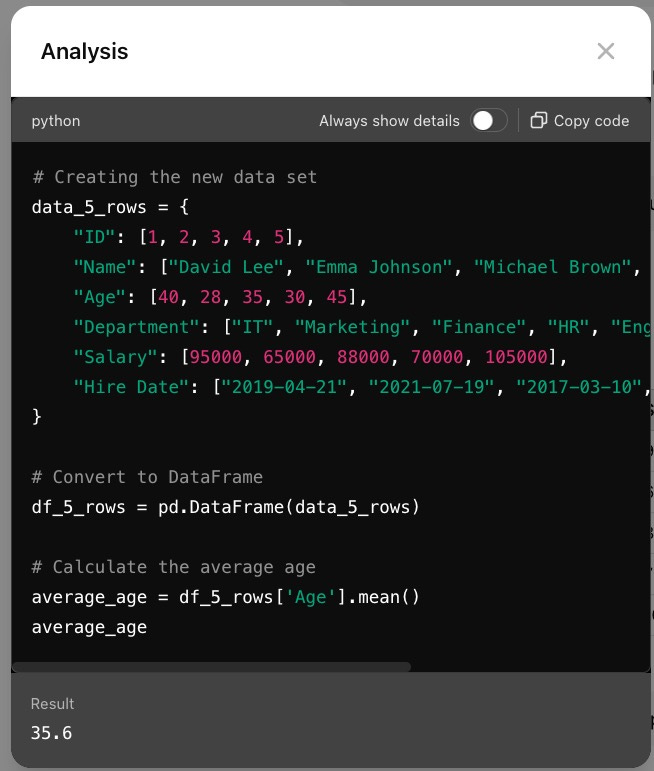
As in Gap 1, one of the best solutions so far is better prompting, but more research is required. Microsoft commissioned a study on this and shared its results last year, and its team was able to increase accuracy against structured data sets with a variety of enhanced prompting techniques.
Another option is what was mentioned previously: use the LLM to direct and structure a traditional query against the structured database. Unfortunately, this approach is also flawed, as it rapidly becomes an exercise in writing code to protect against Gap 1, where unpredictable outputs don’t match the schema of the data, or they misinterpret the schema as compared with the intent of the question.
Pecan.ai appears to be one company that is trying to deal with at least part of this challenge in that its software allows customers to connect to structured databases as an input source that its models can interrogate, but even the company’s blog calls out that LLMs are not great at dealing with unstructured data. The open source library LangChain and its paid enterprise companion also offer enhanced connectivity with structured data sources.

Gap 3: Understanding unusual-structure, high-value data sets
LLMs typically struggle with data types that they were not explicitly trained on, so the more difficult the data is to access and the more obscure, the less intelligently the computer can reason about it. Frequently, this would also mean that these data sources are less valuable, although this is not always the case. Consider, for example, satellite imagery, the market for which is billions of dollars in the U.S. just for the images and closer to $100 billion when the geospatial analytics products are combined with the imagery.
LLMs are not trained on these sorts of images and they cannot, as a result, answer questions like “Does 567 Oak Street have a pool in the backyard?” based on the latest satellite or aerial imagery. To get an answer like this, the imagery must first be run through a computer vision model that detects pools, and then that detection information about the satellite image would need to be appended to the record. Then the LLM would have to query that metadata, again triggering the challenges in Gaps 1 and 2.
The same thing is true for medical device imaging such as ultrasound, x-rays, CT scans, and MRIs. A decade or more of work has gone into analyzing these modalities but using traditional computer vision models, not LLMs. Another example is engineering drawings, such as computer-aided design (CAD) files, which contain tremendous amounts of important information that would be helpful to query without having to manually open and inspect each file.
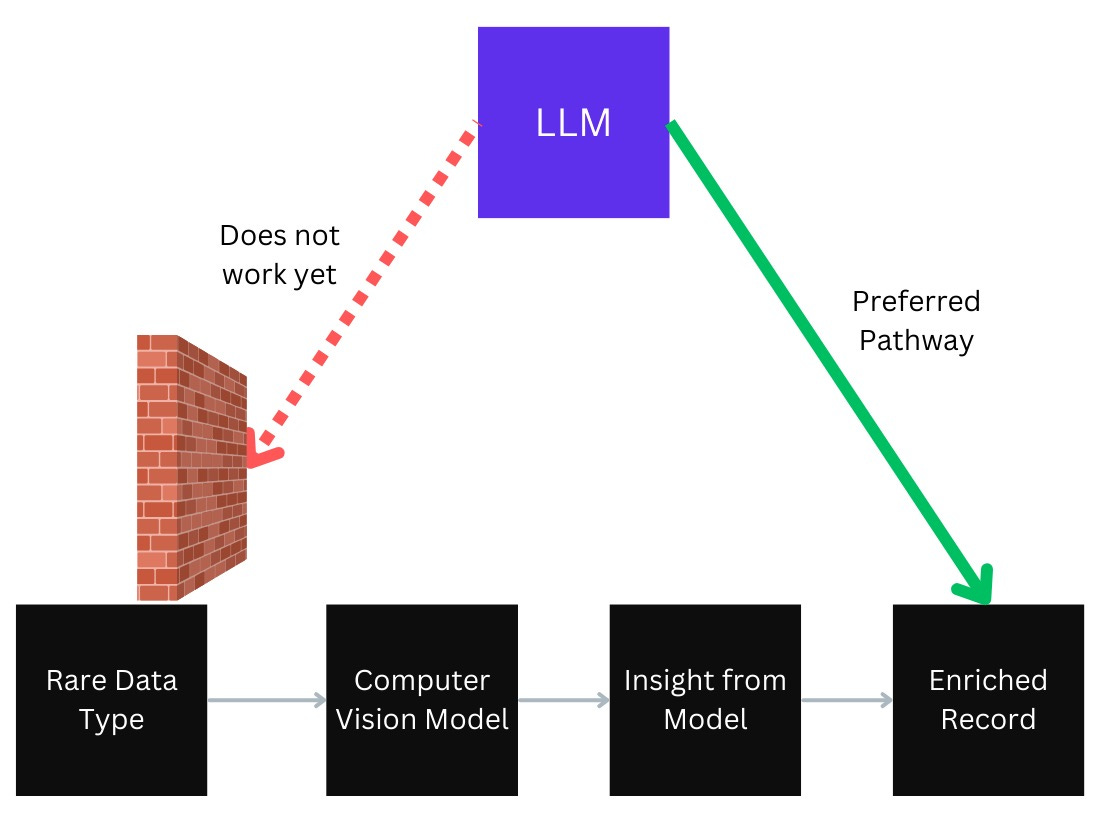
It wasn’t long ago that still images from cameras, videos, and audio would have been on this list, so we are hopeful for rapid progress in solving these gaps, and certainly the economic incentives exist for companies to exploit them. Some companies are focused on these niche areas, though to our knowledge none are yet training LLMs to understand the pixels.
For example, Danti.ai is making strides toward the searchability of satellite imagery and other location-based information through semantic searches, Synthetaic is working to detect the as yet undetected in those images, and Butterfly Network is making sense of ultrasound. However, we are not aware of a company that has trained an LLM to recognize the pixels in these data types so much as using traditional methods to get around this gap. Academic researchers are working on these domains, and it is likely only a matter of time before their work is more commercialized.
Gap 4: Translation between LLMs and other systems
Effectively directing LLMs to interpret a question and then undertake specific tasks based on the nature of the user’s question remains a challenge. When the LLM needs only to answer the question with the data already embedded within it, it excels; however, frequently LLMs are asked to be the first line of defense in interpreting the user’s intent, where different intents should lead the software to route the query to different downstream systems.
Take, for example, how ChatGPT knows when it was asked an image generation question that should trigger DALL-E, or when its “Analyzing” function is invoked to perform math or use formulas. Similarly, how does Gemini decide when to use a dynamic UI to display its answer? While it can look like magic in retrospect, it seems clearer over time that these innovations likely depend on strong query classification and routing logic built into the interpretation of the user’s request. Each style of question triggers different logic under the hood, and classifying the user’s question into these different realms is itself a massive undertaking, since the questions can be so entirely open-ended and dissimilar from each other. Further, if the product calls for routing the question to multiple places, a summarization function is needed to recombine the results.

We have seen no companies attempting to own this space in the abstract, but we suspect that many companies are building this capability for different use cases and different downstream systems. We believe there is room for a company to become the “Zapier for AI model routing to third-party systems” and expect that firms like Make and of course Zapier will lean in as this problem set becomes more openly discussed and clearer to all.
Most enterprises are too early on the generative AI adoption curve to recognize that this is an issue, but once they put their data into such a system, it won’t be long before they are asking the AI to take slightly different actions based on the inputs, for example following instructions like “Issue the client a refund if we double charged them” based purely on a customer support chat conversation. Probably the closest is Adept AI, in that it has built a multi-modal model that can intelligently take action within a product UI based on the prompt.

Gap 5: Orchestration of LLMs
Commanding and coordinating multiple LLMs or, in some cases, multiple agents to perform complex, multi-step tasks involving disparate data and objectives is ripe for investment. Increasingly, businesses and consumers are seeing the power of each atomic action an LLM can solve, but they are not seeing easy solutions for tying these actions together and effectively chaining agents into a more profitable system.
For example, suppose you want to check your high schooler’s bank account balance and then deposit funds up to a point to help them replenish the funds, but you only want to do this if the transactions are in line with your guidance. You don’t want to add money if most of the spending is on concerts and fancy meals, but if it’s being spent on gas, school supplies, a present for Mom, and other “approved” items, then you’d like to replenish the funds commensurate with the “good” spend. This multi-step process would require multiple AI agents, each working together, passing inputs and outputs to each other and making decisions and handoffs, perhaps without a human in the loop, or maybe only at the very end to confirm the transaction.
Each individual task could be automated, but together it’s extremely difficult to compose, with incredible amounts of custom code. The same is true for the increasingly frequent practice of taking the same question and running it across multiple foundational language models and then picking the best response or combining the responses. While these problems are omnipresent for the consumer, they are prolific for the enterprise.
An orchestration-for-LLM-agents company would quickly become indispensable. Its intellectual property would have a lot to do with guaranteeing the inputs and outputs from each gate in the agentic system, not to mention user-friendly hooks for where human intervention is either desired (for example, logging in to banking) or required (confirming the flight plan for a commercial aircraft) and maintaining and respecting a set of rules that the user should not be allowed to override during normal prompting.
Palantir’s AI Platform (AIP) has a “Use LLM block” functionality that allows no-code orchestration of multiple LLM actions in a series. Further, Anthropic has been working on so-called “Constitutional AI,” which gives agents a set of policies and rules to follow that allow the agents themselves to scrub and review the responses from previous LLM prompts. CrewAI is perhaps the easiest to access solution for AI agent orchestration as it has substantial open source resources developers can build with. LangGraph, which builds upon LangChain, assists in applying saved state to orchestration. Meanwhile, UC Berkeley has released its own project called Gorilla for connecting LLMs with various APIs, and on the earlier stage, companies like Transcend are seeking to make the connective tissue consumer-usable for everyday tasks. The prevalence of a growing set of open source options is often a harbinger for the growth of mature companies with paid offerings.
Clearly, each of these technologies may constitute a part of the whole that is required to orchestrate a true chain of events without a lot of code or human intervention. Of course, the injection of human-in-the-loop hooks into this process or respecting policy restrictions (for example, “no withdrawals from bank account over $1,000 without a human”) will be critical for any of these agentic system products to gain widespread adoption from the public and acceptance from the third-party tools that will need to allow them to interact with their information.
Gap 6: Testing the quality and correctness of results
A major challenge in productizing LLM use cases is determining when the outputs contain inaccuracies, hallucinations, biases, or other errors. As I wrote this article, I continually asked various models to help me research companies that are working on these gaps. Interestingly, in most cases, the AI gave me names of companies I had never heard of, and I was thrilled to learn more about them. Unfortunately, almost every company it generated either doesn’t work on the problems stated or does not exist. So far as the LLM was concerned, its product “worked” and provided valid responses to my questions in the form of company names. However, the quality and correctness of the answers was unreliable.
I find this repeatedly when researching longer-form posts like this. A lot of my prompts begin with “Are there startups or fast-moving VC-backed companies that…” and inevitably I get responses that “Google” or “Meta” do this, except neither of those companies have been startups for a long time. At least in those cases, I am receiving real companies as the outputs; frequently I receive real-sounding companies that are fake, or I get real ones but whose focus areas are not aligned with the gaps described. This is problematic when researching a blog post, for sure, but the implications are far wider and more concerning beyond writing.
How will we know that the solution to the math question ChatGPT helps our third grader with is actually correct or that the formula used was applied in the appropriate circumstances? What happens if even more people learn the incorrect answer or learn from a model hallucination instead of learning from facts? (Perhaps adding to the problem, the LLM may already be correct more often than most human teachers when applied across the broad spectrum of human knowledge; however, it is often less correct than an expert human.)
As mentioned above, Anthropic’s “Constitutional AI” framework could help. Additionally, the ecosystem of solutions available through Hugging Face and its associated community likely will be a strong reservoir of possible solutions, but it will take years for these technologies to mature to a point where we can intelligently confirm the accuracy of responses across a wide range of question styles. Perplexity.ai solves for this through transparent sourcing of responses, which is a great example to live up to, but it still requires the user to follow those links and have knowledge of which sources are reputable. Unfortunately, the accuracy challenge is also confounded by the proliferation of AI-generated answers in the first place.

Gap 7: Robots in, robots out
Ensuring that high-quality data feeds into our LLMs in the first place is the final gap. For now, most of the enthusiasm is focused on getting human-generated enterprise data into LLMs through fine-tuning or RAG approaches. However, the speed at which we’re adopting LLMs, combined with the incredible volume of output they can produce in seconds, suggests that perhaps exponentially sooner than we expect, most LLMs and enterprise implementations of them will be confronted with machine responses as their inputs most of the time.
For example, we’re happy for the model to train against the successful resolution of a customer support case performed by a top human agent, but are we equally happy for that model to then enhance its training based on what it produced? It won’t take long for the AI-produced “school solutions” to dominate in these settings, particularly because the AI will continue to train on edge cases that it answered successfully and for which a human exemplar does not exist.
It’s already difficult when models have been thoughtfully prompted and tuned to distinguish between the AI responding and a human, so we cannot expect the model itself to know the difference. This is less concerning when the model is producing correct and valid answers to concrete questions, but it becomes critically important when the models hallucinate, take on controversial opinions or biases, or attempt to be more creative than we’d like.
It’s not hard to envision how a set of AI agents writing simple news stories on the outcomes of sporting events, for example, could start by introducing incorrect scores or readouts on how players acted, and for that content to get picked up innocuously by broader AI agents attempting to summarize events across a whole sport, and before we know it, a fan who caught a foul ball as a spectator is now being written about as if they play third base and have a $5 million a year contract with the Houston Astros. If we wait to solve this problem once everything is published, it will be too late to fully unravel the inaccurate narratives.
For the time being, it’s straightforward to address this in business settings by explicitly not including AI responses as inputs for training or creating embeddings, but soon it will become impossible to distinguish as more primary-source writing gets done by machines instead of humans. One company that is defining solutions for this early market is Reality Defender, a venture-backed product startup focused on tools for detecting AI-written text, video, and audio. So far, the market appears to be more energized by stopping fraud and deep fakes than on data pipeline monitoring, however.
For example, Reality Defender describes a situation in which someone records your voice without your knowledge in a regular everyday conversation, trains an audio agent to sound like you, and then passes your bank’s voice-recognition test over the phone to then take control of your finances. My hope is that we will begin to label all data sources and put them on an independently verified blockchain at least under the hood, but even that process can only produce a probability score that the information is AI-produced, not true certainty.
Concluding thoughts
Generative AI has taken the world by storm, and the wide range of its applications is impressive but nascent. For practitioners, it is clear that investment around the developer experience when using LLMs lays bare numerous serious gaps. There are plentiful others we did not cover, for example latency in getting responses from the foundational models or rapidly training on enterprise or personal data sources. Investors and founders alike will take note of plentiful opportunity, while current builders can gain camaraderie from knowing that their struggles in implementing intelligent, text-writing generative AI are not unique. For now, we recommend:
Stronger prompting
Custom code wrapped around model inputs and outputs
Testing the wide variety of open source tools
Experimentation with new functions from the foundational models
Experimenting with the new products from growing companies supporting these gaps
Taken in concert, this is currently the best path forward, and hopefully we’ve also inspired some new founders and investors today!
Hi! If you enjoyed these insights, please subscribe, and if you are interested in product coaching or fractional product support for your venture, please visit our website at First Principles, where we help the most ambitious founders make a difference.
The AI Agent market is expected to have a promising future and is anticipated to achieve robust growth in the coming years.
According to a report by MarketsandMarkets, the autonomous intelligent agent market size is projected to surge from $345 million in 2019 to $2.992 billion by 2024, with a CAGR of 54%, and is expected to exceed $28.5 billion by 2028. It is believed that they will play a significant role in technological advancements, market growth, human-computer interaction, social structure transformation, and full automation.
Currently, we categorize AI Agents into two main types:
- Autonomous Intelligent Agents, striving to automate complex processes. When given an objective by an autonomous intelligent agent, they can independently create tasks, complete tasks, generate new tasks, reprioritize the task list, accomplish new primary tasks, and continuously repeat this process until the objective is achieved. High accuracy is required, thus external tools are more needed to mitigate the negative impact of large model uncertainty.
- Agent Simulations, aiming to be more human-like and credible. They are divided into agents that emphasize emotional intelligence and those that emphasize interaction. The latter is often in a multi-agent environment, where scenarios and capabilities beyond the designer's planning may emerge. The uncertainty generated by large models instead becomes an advantage, and diversity makes it a promising component of AIGC (AI-Generated Content).